Understanding the true cost of relying on legacy applications for managing Investment Risk
Sean Mentore
2 min read
Legacy applications are not just expensive to maintain. They are expensive to trust.
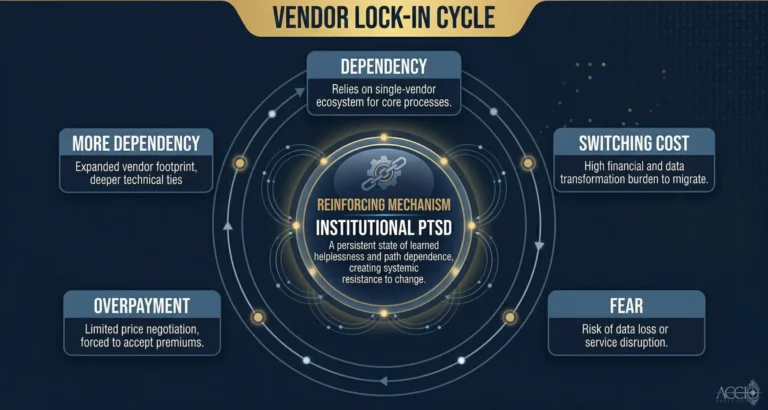
When I talk to technology leaders at regional banks and credit unions about their investment risk systems, the conversation almost always arrives at the same place. They know the systems are old. They know the maintenance costs are real. What they have not fully calculated is the operational cost: the hours spent reconciling data, the workarounds their teams have built to compensate for system gaps, the risk decisions being made on data that has not been validated in any systematic way.
That is the true cost of legacy applications. Not the licensing fee. Not the infrastructure spend. The Manual Tax.
The Manual Tax is the labor cost of operating a system that cannot do something it should be able to do automatically. Your analysts spend time reconciling instead of analyzing. Your operations team runs overnight reconciliation scripts that have not been documented in years. Your compliance team manually validates reports the system should be able to verify itself. Every one of those hours is a cost that does not appear on the technology budget line.
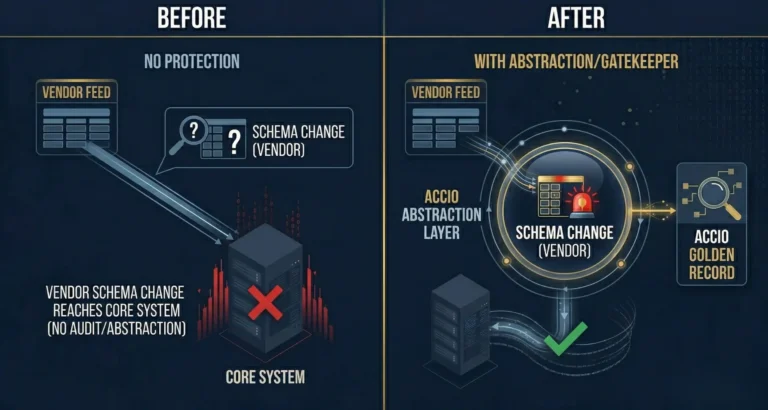
Legacy risk management systems compound this problem in a specific way. They were designed for a world of batch processing. Data loaded overnight, calculations run before markets open, reports available by morning. That model does not reflect how risk actually works. Risk does not pause for your batch window. A position that was clean at close can be underwater before the morning report runs. By the time your system tells you there is a problem, the window to act has narrowed significantly.
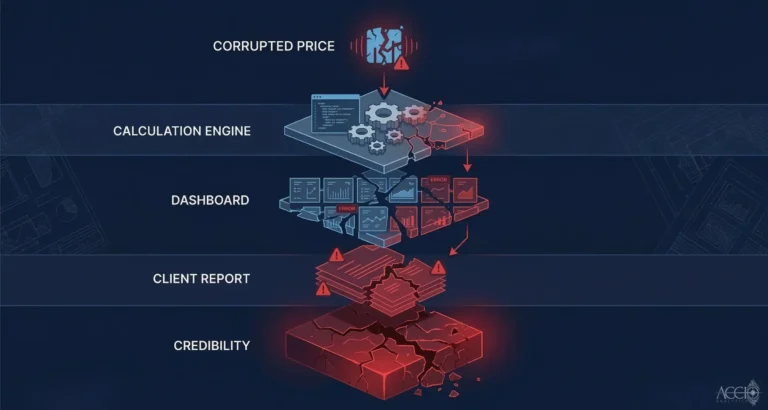
There is a second cost that is harder to quantify but equally real: the cost of operating on unvalidated data. Legacy systems were not designed to catch data quality issues at ingestion. They receive a feed, process it, and pass it downstream. If the feed was wrong, every calculation built on it is wrong. The system does not tell you. You find out later. In a client report discrepancy, a compliance audit, or a position that does not reconcile.
Modern data infrastructure addresses both problems. Real-time processing removes the batch dependency. Systematic validation at the ingestion layer catches data quality issues before they propagate. A complete audit trail makes every output traceable.
None of this requires replacing your entire stack. The Accio Ingestion Engine plugs into what you already have. It sits at the data layer, normalizing and validating before your legacy systems receive anything. Implementation takes two to four weeks. The Manual Tax starts coming down immediately.
By Sean Mentore, Co-Founder & Chief Architect, Accio Analytics
Technical Whiteboard Session
Sean is offering to sit down with your lead architect and head of operations for a 30-minute technical whiteboard session where we will:
- Map your current ETL flow for data ingestion
- Identify the specific points where your system leaks capital
- Identify where your data lineage fails the Proof of Origin test