When the Vendor Changes the Column Name Overnight: Schema Drift and the Abstraction Layer
Sean Mentore
4 min read
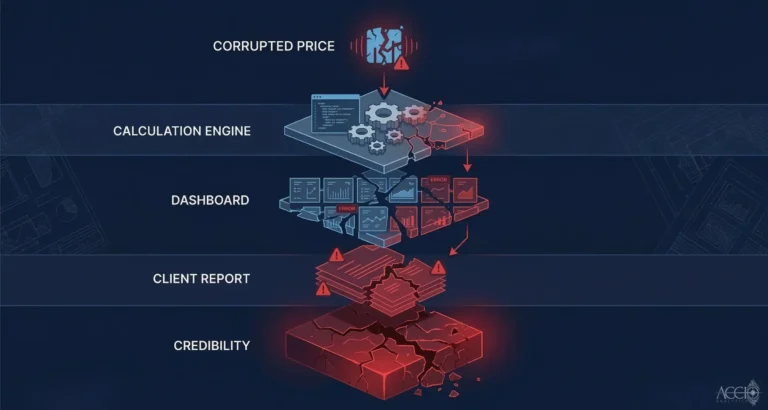
Your Vendor changed a column name overnight. Your ETL loaded the data without error. Your calculation engine produced wrong numbers. Your client noticed before your team did.
This is not a hypothetical. This pattern happens constantly in financial data infrastructure. Vendors change schemas without notice. They add columns, remove fields, rename data points, or restructure feeds because another client needed it or because they updated their internal systems. Your feed changes as a side effect. No communication. No migration path.
Research on ETL pipeline reliability confirms this: when upstream systems add columns or change data types, poorly designed pipelines break immediately or process corrupted data silently. Schema drift is one of the leading causes of silent data corruption in financial data pipelines.
The Gatekeeper Concept
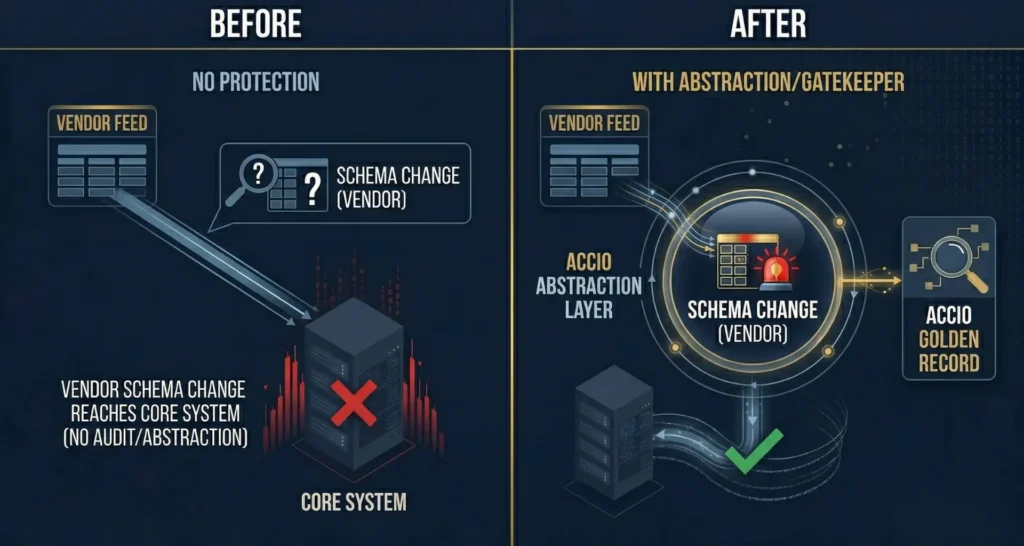
The solution is an abstraction layer between the vendor feed and your core system. We call the first component of this layer the gatekeeper.
It performs schema sanitization on every incoming feed. The first time data arrives, the gatekeeper maps the structure. It presents the schema to the data steward and asks: is this what you expect? The steward confirms. That becomes the baseline.
From that point forward, every feed is validated against the baseline before anything touches the core system. If a vendor sends 12 columns when you expected 10, the gatekeeper flags it. It does not load the data and hope for the best. It asks: what do you want to do with these extra columns? Ignore them? Incorporate them? Investigate why they appeared?
The decision is logged, the action is recorded, and the system remembers.
If a vendor removes a field you were using, the gatekeeper escalates immediately. Missing critical data is not a warning. It is a full stop until a human makes a decision.
Deterministic Memory
Here is where the ingestion engine separates itself from every ETL on the market. When you tell the system how to handle an exception, it remembers. That decision becomes institutional knowledge, encoded into the system.
You told it to ignore those extra two columns. Next time 12 columns arrive, it already knows what to do. But if 14 arrive, it does not apply the old rule to the new situation. It flags the change. Because the situation is different.
Every decision has a mandatory review date. You cannot tell the system to ignore something permanently without scheduling a review. This forces the organization to revisit decisions. Monthly. Quarterly. Whatever the data governance policy requires.
Nothing is permanent. Everything is auditable. Every intervention is logged with who made the decision, when they made it, and when it expires.
Business Rule Validation
Schema validation is the first layer. Business rule validation is the second.
This is where you set thresholds. A price that was a dollar yesterday and is 300 today triggers a review. Not because 300 is impossible. Because a 30,000% overnight move is unexpected and needs a human to confirm it.
The system does not decide whether the price is right. It decides whether the price is expected. If it is unexpected, it quarantines the record. The data steward reviews it, makes a decision, and the system learns from that decision.
If the steward says “use yesterday’s price,” the system records that as a correction. It logs the original value, the corrected value, who authorized the correction, and when the decision needs to be reviewed. Complete lineage. Complete accountability.
Why This Matters Now
The era of batch-loading data overnight and hoping it is correct is ending. AI requires clean data as a precondition. Regulatory scrutiny on data lineage is increasing. Clients expect accurate reporting in real time.
The institutions that have an abstraction layer with schema detection, business rule validation, and deterministic memory will adapt. The ones running raw ETL will spend their time in postmortems.
I covered the broader ingestion problem and the Manual Tax it creates in an earlier post. Start there if you have not read it: Why Every Financial Data Problem Is an Ingestion Problem.
For the vendor lock-in angle, see: You’re Not a Partner, You’re a Hostage.
Byline: By Sean Mentore, Co-Founder & Chief Architect, Accio Analytics
Is schema drift is a recurring problem in your environment?
I am offering a 30-minute whiteboard sessions. No pitch. Just architecture. We’ll map your current vendor feeds and show you where an abstraction layer would sit.
Citations
- Integrate.io, Airbyte, Weld: Schema drift is a leading cause of silent data corruption in ETL pipelines.
- Gartner: Poor data quality costs organizations $12.9 million annually (referenced in context of why detection matters)