Every financial institution has the same conversation at least once a quarter. A number is wrong. A client noticed before the team did. And someone in the room says: “It’s a data problem.”
I have sat in these rooms for twenty years. I have listened to teams diagnose the same failure pattern over and over. And the diagnosis is always correct in the most unhelpful way possible. Yes, it is a data problem. But the data did not corrupt itself. Something happened at the point of entry that nobody saw, nobody caught, and nobody logged.
The root cause is almost always the ingestion layer. Not the analytics engine. Not the reporting system. Not the database. The place where data first enters the system. The ETL that extracts, transforms, and loads without ever asking whether the data is correct, complete, or consistent with what came yesterday.
The Silent Failure Pattern
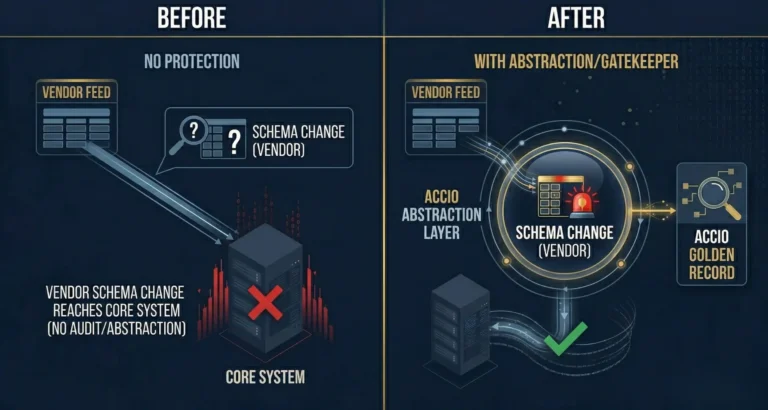
Here is what happens. A vendor sends a feed overnight. The feed contains a schema change. Maybe a field that used to be numeric now has a null character embedded in it. Maybe an encoding shift broke a field delimiter. The ETL does not validate schemas. It does not check for null characters. It loads what arrives and moves on.
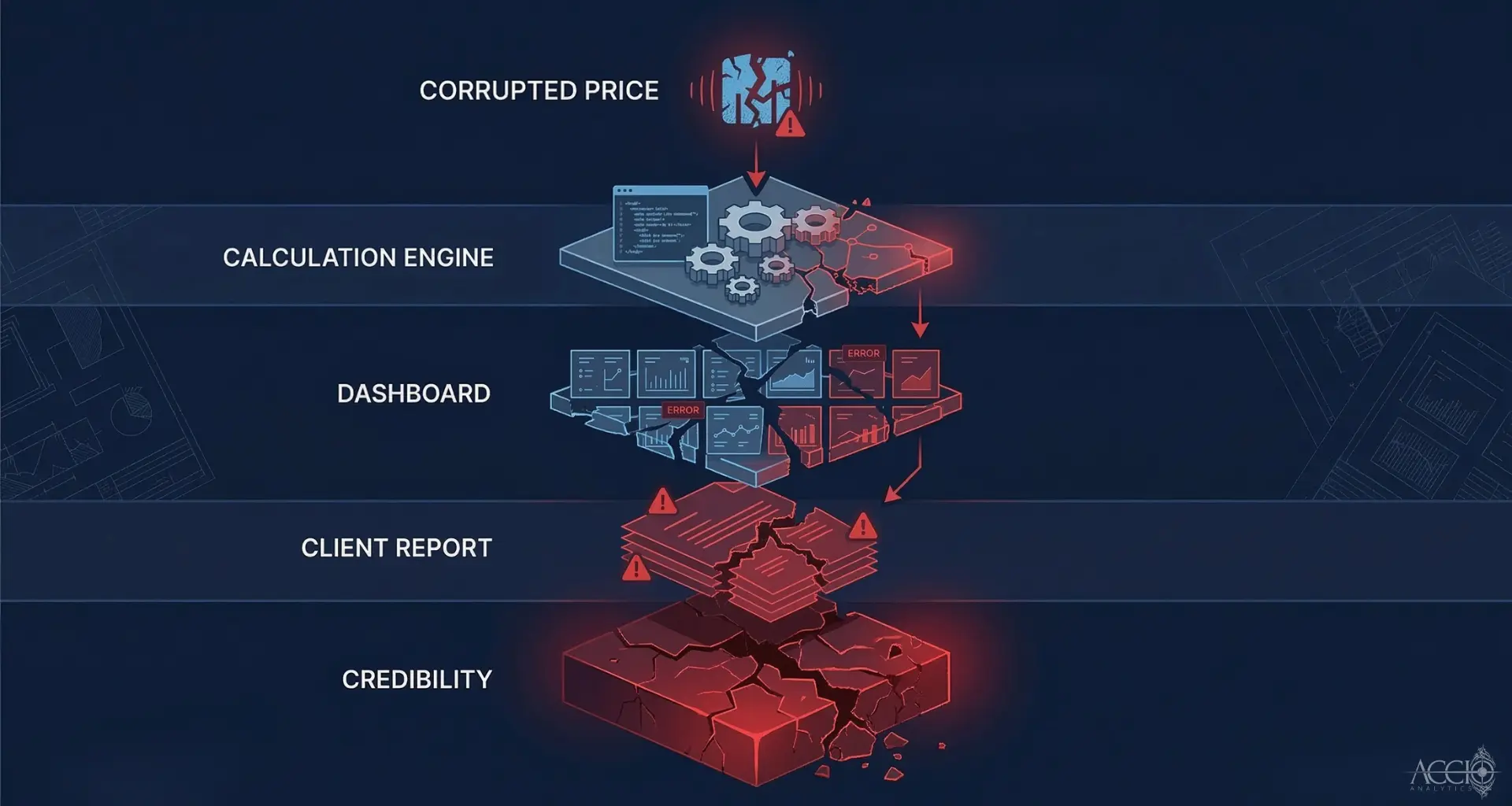
The downstream system receives the data and does exactly what it was designed to do. It calculates on whatever it was given. A corrupted price becomes a corrupted return calculation becomes a corrupted dashboard becomes a corrupted client report. This is what I call the cascade effect. One bad data point at the ingestion layer can propagate through every system in your infrastructure before anyone notices.
Research from Gartner estimates that poor data quality costs organizations an average of $12.9 million annually (Gartner). In financial services, where data errors can cascade into regulatory filings, client reports, and investment decisions, the cost is typically higher. Industry analyses suggest organizations lose 15 to 25 percent of revenue to data quality inefficiencies (Data-Sleek, Folio3).
The Manual Tax
I have watched teams spend 80% of their time validating data instead of using it. A widely cited benchmark from CrowdFlower, reported by Forbes, found that data professionals spend roughly 80% of their time on data preparation and cleaning. In financial services, I have seen this number play out in real time.
I remember one time it took the team six days to find what the problem was. Six days. Not because the team was slow. Because the system had no memory of what happened at the point of entry. No lineage. No validation log. They worked backwards through the reporting layer, the calculation engine, the database, and the transformation logic, all the way back to the source feed. A properly instrumented ingestion layer would have caught the problem in seconds.
I call this the Manual Tax. It is the operational cost of running financial systems on uninspected data. Your most expensive analysts are not analyzing. They are checking. They are reconciling. They are doing forensic work that the ingestion layer should have done automatically.
The AI Precondition
Every board in financial services is asking about AI. Data cleanliness has to be the number one priority. AI is a predictive engine. It needs clean, contextual, complete data. If you train a model on data that was never validated at the point of entry, you are automating bad decisions at scale.
I would personally want 100% clean data going into any AI engine. The industry will settle for 95%. But most institutions do not know what percentage of their data is clean because their ingestion layer does not measure it. AI readiness is not a model problem. It is a data quality problem. And data quality is an ingestion problem.
The Architectural Answer
The solution is not better ETL. ETL was built to move data, not to interrogate it. The solution is an ingestion layer that validates at the point of entry. That checks the schema before loading. That detects null characters, encoding shifts, and missing fields before they cascade. That logs every action, every correction, and every exception with a complete audit trail.
When the ingestion layer is instrumented to catch problems at the door, the forensic gap closes. The Manual Tax drops. The cascade effect stops. And the data that reaches your analytics engines, your AI models, and your client reports is data you can actually trust.
I wrote more about why this gap exists and how it compounds in a longer piece on Substack. If this pattern sounds familiar, it is worth the read.
Byline: By Sean Mentore, Co-Founder & Chief Architect, Accio Analytics
Technical Whiteboard Session
I am offering to sit down with your lead architect and head of operations for a 30-minute technical whiteboard session where we will:
- Map your current ETL flow for data ingestion
- Identify the specific points where your system leaks capital
- Identify where your data lineage fails the Proof of Origin test
Citations Used
- Gartner: Poor data quality costs organizations an average of $12.9 million annually
- CrowdFlower/Forbes: Data professionals spend ~80% of their time on data preparation
- Industry analyses (Data-Sleek, Folio3): Organizations lose 15–25% of revenue to data quality issues